1.3 局部加权线性回归(Locally weighted linear regression)
假如问题还是根据从实数域内取值的 来预测 。左下角的图显示了使用 来对一个数据集进行拟合。我们明显能看出来这个数据的趋势并不是一条严格的直线,所以用直线进行的拟合就不是好的方法。
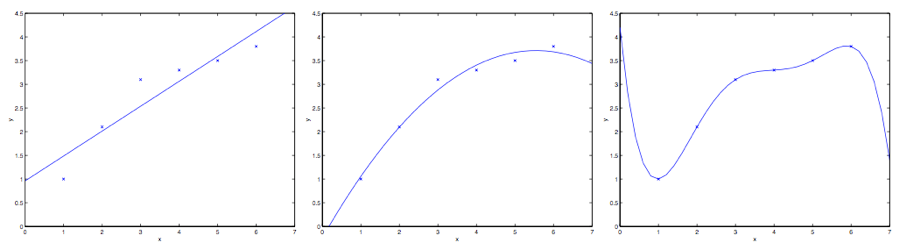
那么这次不用直线拟合,增加一个二次项,用二次多项式 来拟合
不过,增加太多特征也是有风险的:最右边的图就是使用了五次多项式 来进行拟合。看图就能发现,虽然这个拟合曲线完美地通过了所有当前数据集中的数据,但我们明显不能认为这个曲线是一个良好的预测工具。最左边的图像就是一个欠拟合 (under fitting) 的例子,明显能看出拟合的模型漏掉了数据集中的结构信息;而最右边的图像就是一个过拟合 (over fitting) 的例子
正如前文谈到的,也正如上面这个例子展示的,一个学习算法要保证能良好运行,特征的选择是非常重要的
在原始版本的线性回归算法中,要对一个查询点 进行预测,比如要衡量 ,要经过下面的步骤:
- 使用参数 进行拟合,让数据集中的值与拟合算出的值的差值平方 最小 (最小二乘法的思想);
- 输出 。
相应地,在 LWR 局部加权线性回归方法中,步骤如下:
- 使用参数 进行拟合,让加权距离 最小;
- 输出 。
上面式子中的 是非负的权值。直观点说就是,如果对应某个 的权值 特别大,那么在选择拟合参数 的时候,就要尽量让这一点的 最小。而如果权值 特别小,那么这一点对应的 就基本在拟合过程中忽略掉了。
对于权值的选取可以使用下面这个比较标准的公式:
NOTE
如果 是有值的向量,那就要对上面的式子进行泛化,得到的是 ,或者:。
要注意的是,权值是依赖每个特定的点 的,而这些点正是我们要去进行预测评估的点。此外,如果 非常小,那么权值 $w^{(i)} $ 就接近 ;反之如果 非常大,那么权值 $w^{(i)} $ 就变小。所以可以看出, 的选择过程中,查询点 附近的训练样本有更高得多的权值
局部加权线性回归是咱们接触的第一个非参数 算法。而更早之前咱们看到的无权重的线性回归算法就是一种参数 学习算法,因为有固定的有限个数的参数(也就是
LWR 的解析解
首先将损失函数写为矩阵形式:
其中
欲使损失函数最小,需对 求导:
第五个等号利用了 ,第六个等号利用了向量内积的对称性,第七个等号利用了二次型求导和内积求导的相关结论。
故有