4.1 高斯判别分析 GDA
多元高斯分布
维高斯分布,亦称 维正态分布,以期望向量 和协方差矩阵 为参数,其中 是半正定矩阵,记作 。其联合分布为
高斯判别分析模型 GDA
虽然名为 “判别
在 GDA 中,我们用多元高斯分布来拟合 ,即
写出分布:
在此处,参数为 ,两个高斯分布的期望向量不同,但协方差矩阵相同。对数似然函数为
为使对数似然函数最大化,通过计算对各参数的梯度,我们可以获得参数的值:
下图是 GDA 给出的决策边界:
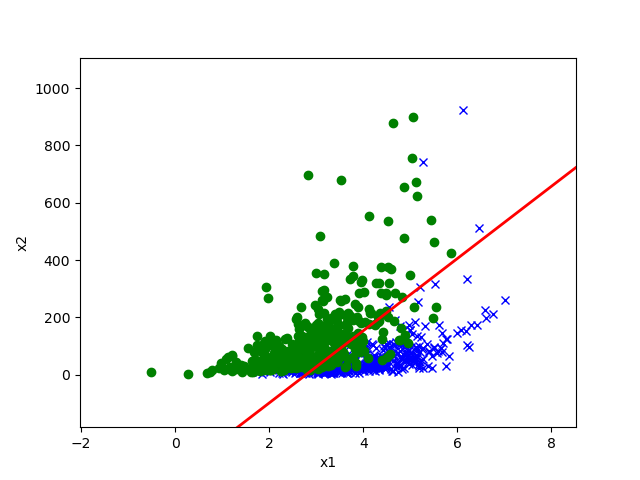
在这条红线上,我们的预测是 ;在其中一侧,,因此我们预测这一侧为 ;在另一侧则反之,,因此我们预测这一侧为 .
GDA 与逻辑回归
如果我们把上面的结果代入贝叶斯公式,有
其中 是 的函数。而上式正是逻辑回归函数 —— 一个判别算法。
那么,通过 GDA 预测和通过逻辑回归预测的效果是否相同呢?答案是否定的。
我们刚刚已经说明了如果 是一个多元高斯分布(且具有相同的协方差矩阵
这就表明高斯判别模型相比逻辑回归对数据做了更强的假设。 这也就意味着,在这两种模型的假设都成立的时候(即 确实符合高斯分布时
反之,由于逻辑回归做出的假设要明显更弱一些,所以因此逻辑回归的通用性也更强,同时也对错误的建模假设不那么敏感。有很多不同的假设都能够将 引向逻辑回归函数。例如,如果 是一个泊松分布,而 也是一个泊松分布,那么 也将符合逻辑函数。逻辑回归也适用于这类的泊松分布的数据。但对这样的数据,如果我们强行使用 GDA,然后用高斯分布来拟合这些非高斯数据,那么结果预测的准确性就会降低。
总结:高斯判别分析方法(GDA)能够建立更强的模型假设,并且在数据利用上更加有效(比如说,使用比较少的训练集就能有 "还不错的" 效果